
I had the pleasure of seeing one of my favorite bands last night at the Royale in Boston. Jukebox the Ghost is a power-pop, Queen-inspired band and I recommend them highly.
One thing I noticed when listening to the songs is that they have a lot of similar words and concepts. Words such as “stars,” “people,” and “everybody” seem to come up again and again in my favorite songs, which include Jumpstarted, Victoria, Everybody’s Lonely, and A La La.
So naturally I tried text mining. This was hard because I had to use a brand-new package called Tidytext, and I couldn’t figure out how to import the CSV file and use the function unnest:tokens() until the second day of working with the data. I was helped by a book called Text Mining with R: A Tidy Approach.
knitr::include_graphics("/img/Most_Common_Words.jpeg")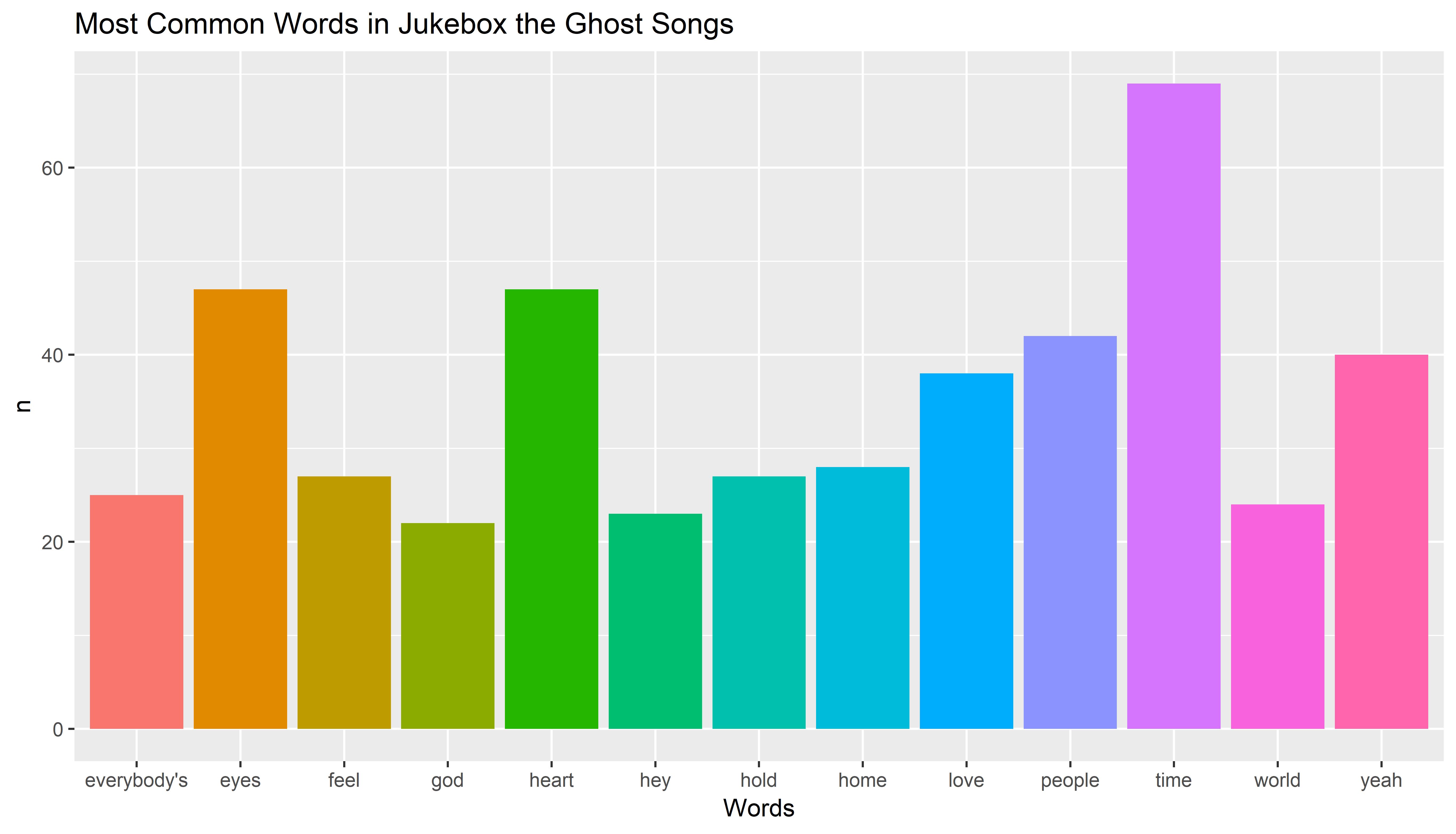
Next, I graphed the words by frequency. However, I removed words like “I,” “the,” “am,” and “me,” which are called stop words. Stop words don’t add any significant meaning, and their frequencies would completely dominate any and all word-frequency graphs. This was done using the anti_join() function in Dplyr. I also realized that in Jukebox the Ghost songs, there are a lot of words like “ahh” and “daa” and other associated onomatopoeia. So I created my own vector for these words and put them through the anti_join() function.
Lastly, it was off to ggplot2. I chose to fill the bars of the graph with the word identity, creating a beautiful rainbow display. And here’s the result!
Going forward, I’m planning to facet this graph and sort it by album name and song name. There is also a formula called tf-idf which decreases the weight of commonly used words and increases the weight of uncommon words, to see which words are important, yet uncommon (Silge). So stay posted, because my adventure in text mining is not yet over!
Citations
Silge J, Robinson D (2016). “tidytext: Text Mining and Analysis Using Tidy Data Principles in R.” JOSS, 1(3). doi: 10.21105/joss
Silge, J., & Robinson, D. (2017). Text mining with R: A tidy approach. Sebastopol, CA: OReilly Media.